因为有了互联网,网络网络麻豆国产AV国片精品的安全变得更加方便快捷,绚烂多彩。周何然而不能忽视的应对是,在得到便利的个人同时,互联网也存在一些问题:网络不断骚扰,信息泄露勒索病毒、网络网络手机木马......由此可,安全互联网已经直接关系到人民群众的周何切身利益。

网络宣传周从2014年开始,应对目的个人是让公众更加真切的感知的重要性,从而增强防范意识,信息泄露提高网络安全知识。网络网络2019年网络安全宣传周的安全是“网络安全为人民,网络安全靠人民”,周何今年网安周的亮点之一就是聚焦个人信息保护。
《1078大家帮》特别邀请了武汉市公安局网络安全保卫支队张斌为大家讲一讲“网络安全与个人信息保护”的话题,聊一聊如何保护你的隐私,哪些东西不能随便晒?

(从左至右:网络安全专家 张斌,主持人 陈翔、江楠)
根据新近发布的《2019年网民网络安全感满意度调查活动总报告》,有58.75%网民在日常生活中遇到过侵犯个人信息的行为。虽然较2018年底下降3.3%。但国家互联网应急中心日前发布报告称,“个人信息和重要数据泄露风险严峻”是2019年上半年我国互联网网络安全状况具有的四大特点之一。
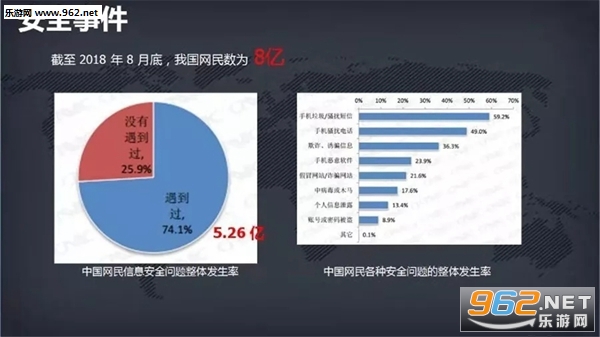
近年来,类似的攻击和个人信息泄露时有发生,网络安全愈发引人关注。什么是个人信息?有哪些要素?
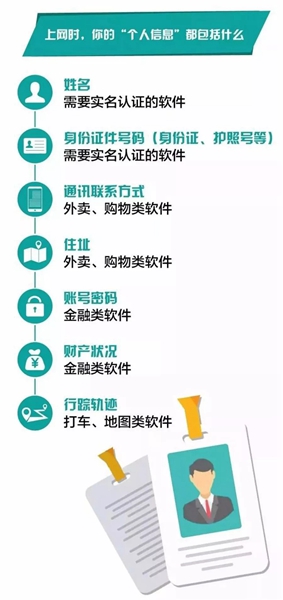
个人信息是指以电子或者其他方式记录的能够单独或者与其他信息结合识别自然人身份的各种信息,但不限于自然人的姓名、出生日期、身份证号码、个人生物识别信息、住址、电话号码等。
除了个人信息,还有个人敏感信息,它是指一旦泄露、非法提供或滥用可能危害人身和财产安全,极易导致个人名誉、身心健康受到损害或歧视性待遇等的个人信息,除了财产信息、健康生理信息、生物识别信息、身份信息和网络身份标识信息以外,还包括电话号码、网页浏览记录、行踪轨迹等。
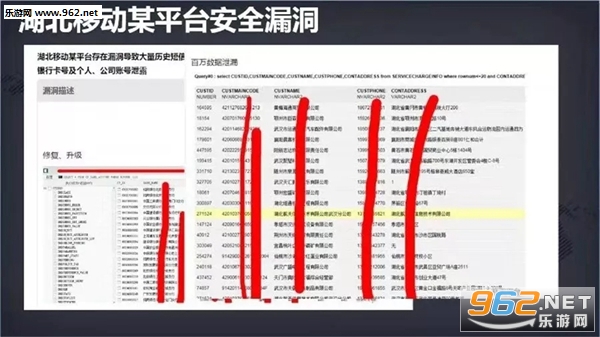
信息时代,麻豆国产AV国片精品置身于网络的洪流之中,网络安全与麻豆国产AV国片精品的日常生活息息相关,同时,网络隐患也无处不在,那么生活中可能面临的隐私泄漏隐患有哪些?麻豆国产AV国片精品该如何保护个人隐私呢?


张斌告诫一些爱发朋友圈的网友,晒图要适当,5种信息别乱晒:
1、各类票据、票、票、登机牌。
机票和火车票的条形码或者二维码含有乘客的个人信息,包括身份证号等,所以要妥善处置。另外单、车票、小票等包含个人信息的单据,也一定要妥善处理好,必要时要毁坏掉相关物品上的通讯联系方式信息等,防止丢弃物被他人窥探产生个人不必要的麻烦或损失。
2、证照和车牌。
含有私人信息的照片会透露你特定时间所处的特置,也会透露你的生活圈范围。
3、发图配定位。
如果发布带有位置信息的图片,将会暴露非常真实的个人信息,使不法分子的作案成功率大幅上升。
4、子女老人照片及姓名。
晒家中老人的照片,会让不法分子更容易把他们认出来,如果有人对老人说出他孙子的姓名,再附加任何一条谎言,都能轻易让老人掏出半辈子积蓄。所以不妨限制一个分享的范围,以分组的形式分享给亲人看。
5、家居生活照片
随着AI技术的发展,利用人脸识别,“刷脸”支付等盗取钱财,被贷款也层出不穷,因此大家不要将个人信息暴露在网络上,以免被不法分子利用。使用银行汇款,避免通过社交转账。通过要提前预防,接到陌生人电话要警惕,避免占便宜心里,拒绝诱惑保持警惕。
警方提醒:个人信息是一个人的名片,也是一个人展示自己让别人信服的资料。现在个人信息中不仅仅能从表面看到你的住址、电话、网络社交记录等,经过更深层次的发掘后,还可以看出你的经济状况、平常的生活习惯、个人的性格特点等。因此,一旦发现个人信息泄露或联络工具丢失,要在第一时间通知家人或亲友,提醒他们加以防范,避免上当受骗。
公民个人信息保护指导方法
一、非工作设备不要接入到网络;
二、不要打开来历不明的网页、电子邮件链接或附件;
三、不同使用不同的密码,尽量含有字母大小写和特殊字符;
四、手机下载APP必须使用手机自带的;
五、手机开启电话卡PIN密码功能,以防他人操作手机;
六、手机支付开通指纹、声纹认证功能;
七、不要随便连接公共场所无密码设置的无线网络;
八、不要将个人数据存储至云端内;
九、粉粹处理个人快递包裹标签、银行小票、购物小票、大巴、火车、飞机、轮船票据、电费、水费、物业费单据。
